
Beyond the Limit: Expanding single-packet race condition with a first sequence sync for breaking the 65,535 byte limit
Posted on August 2, 2024 • 12 minutes • 2429 words
Table of contents
Introduction
Hello, I’m RyotaK (@ryotkak ), a security engineer at Flatt Security Inc.
In 2023, James Kettle
of PortSwigger published an excellent paper
titled Smashing the state machine: the true potential of web race conditions.
In the paper, he introduced a new attack technique called single-packet attack that can exploit a race condition without being affected by the network jitter.
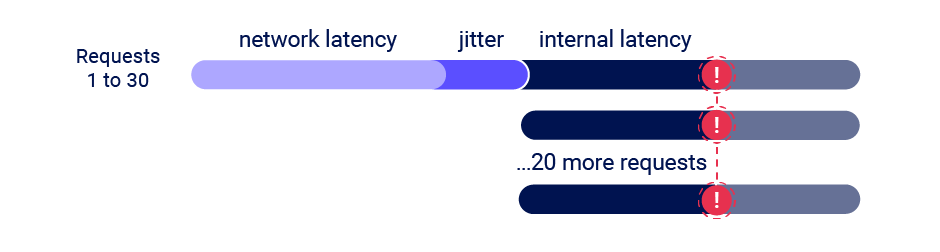
Recently, I encountered a limit-overrun type of race condition that requires sending approximately 10,000 requests simultaneously to exploit reliably, so I attempted to apply the single packet attack to it.
However, due to the single packet attack’s limitation, which restricts the maximum size of requests that can be sent to around 1,500 bytes, I couldn’t exploit the vulnerability.
Therefore, I began exploring ways to overcome this limitation and discovered a method to extend the 1,500-byte limitation of the single packet attack and even the 65,535-byte limitation of TCP.
In this article, I will explain how I expanded the single-packet attack beyond its usual limit and discuss possible ways to utilize it.
TL;DR
To overcome the limitation of a single packet attack, I used IP fragmentation and TCP sequence number reordering.
Using IP layer fragmentation, a single TCP packet can be split into multiple IP packets, which allows the full utilization of the TCP window size.
Additionally, by re-ordering the TCP sequence numbers, I prevented the target server from processing any of the TCP packets until I sent the final packet.
Thanks to these techniques, we can significantly exploit a minor limit-overrun vulnerability, potentially leading to severe vulnerabilities like the authentication bypass of one-time token authentication.
During testing, I was able to send 10,000 requests in about 166ms.
Limitation of single-packet attack
As James mentioned in the The single-packet attack: making remote race-conditions ’local’ , the single-packet attack limits the number of requests that can be synchronized to 20-30 requests:
TCP has a soft limit of 1,500 bytes as well and I never explored how to push beyond this because 20-30 requests is sufficient for most race conditions.
Due to this limitation, it’s hard to exploit the scenario where you can bypass the rate-limiting of, for example, one-time token authentication even if the one-time token only contains the numbers. This is because you’re likely to be able to send only 20-30 requests even if you bypassed the rate limiting.
Fragmentation of IP packet
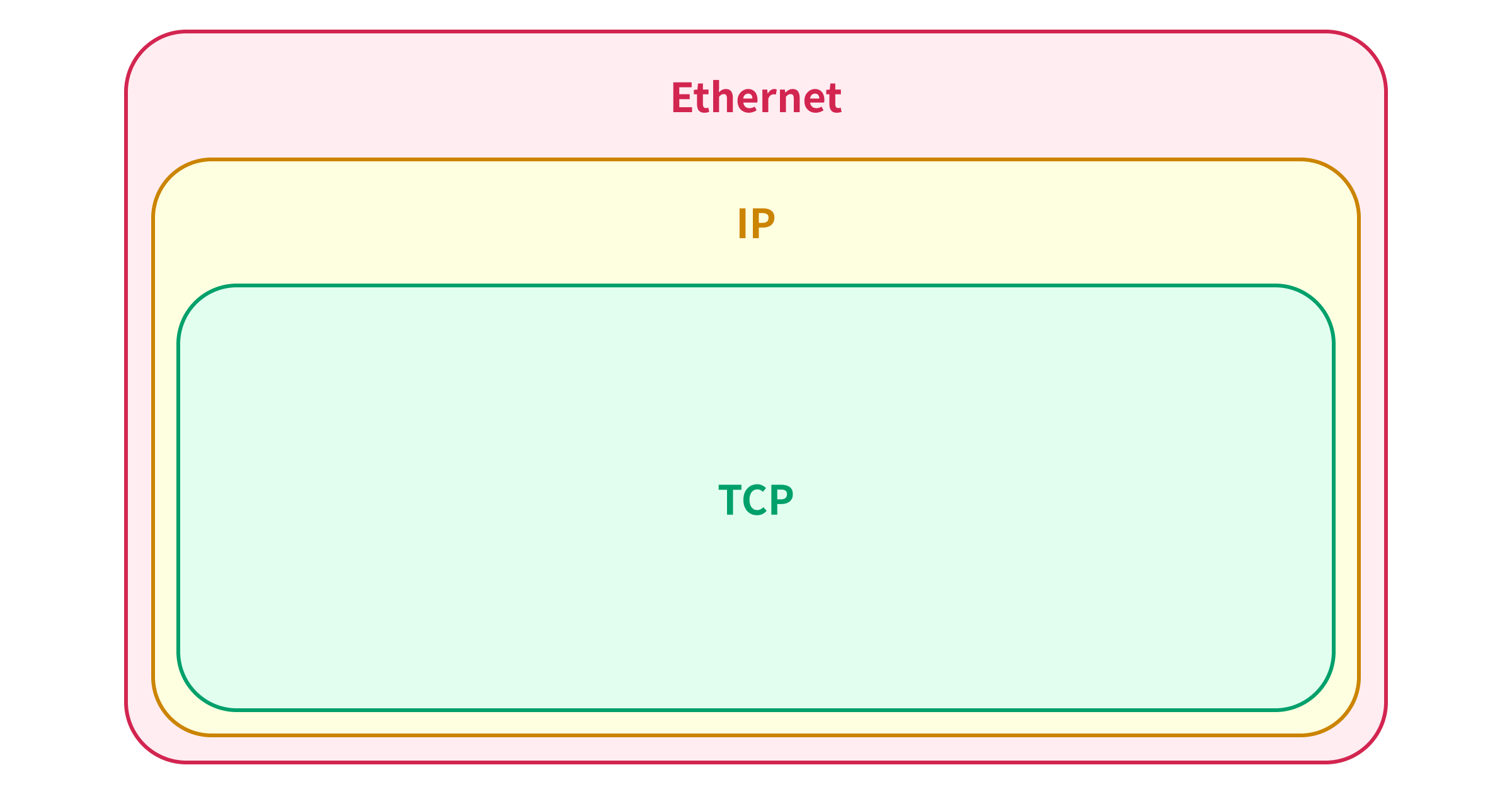
To explain the 1,500-byte limitation of the single packet attack, we need to understand the relation between the Ethernet frame, IP packet, and TCP packet.
When you send a TCP packet over the Ethernet, the TCP packet is encapsulated in the IP packet, and the IP packet is encapsulated in the Ethernet frame:
The maximum size of the Ethernet frame is 1,518 bytes including the Ethernet header (14 bytes) and the frame check sequence (4 bytes), so the maximum size of the IP packet that can be encapsulated in a single Ethernet frame is 1,500 bytes.1
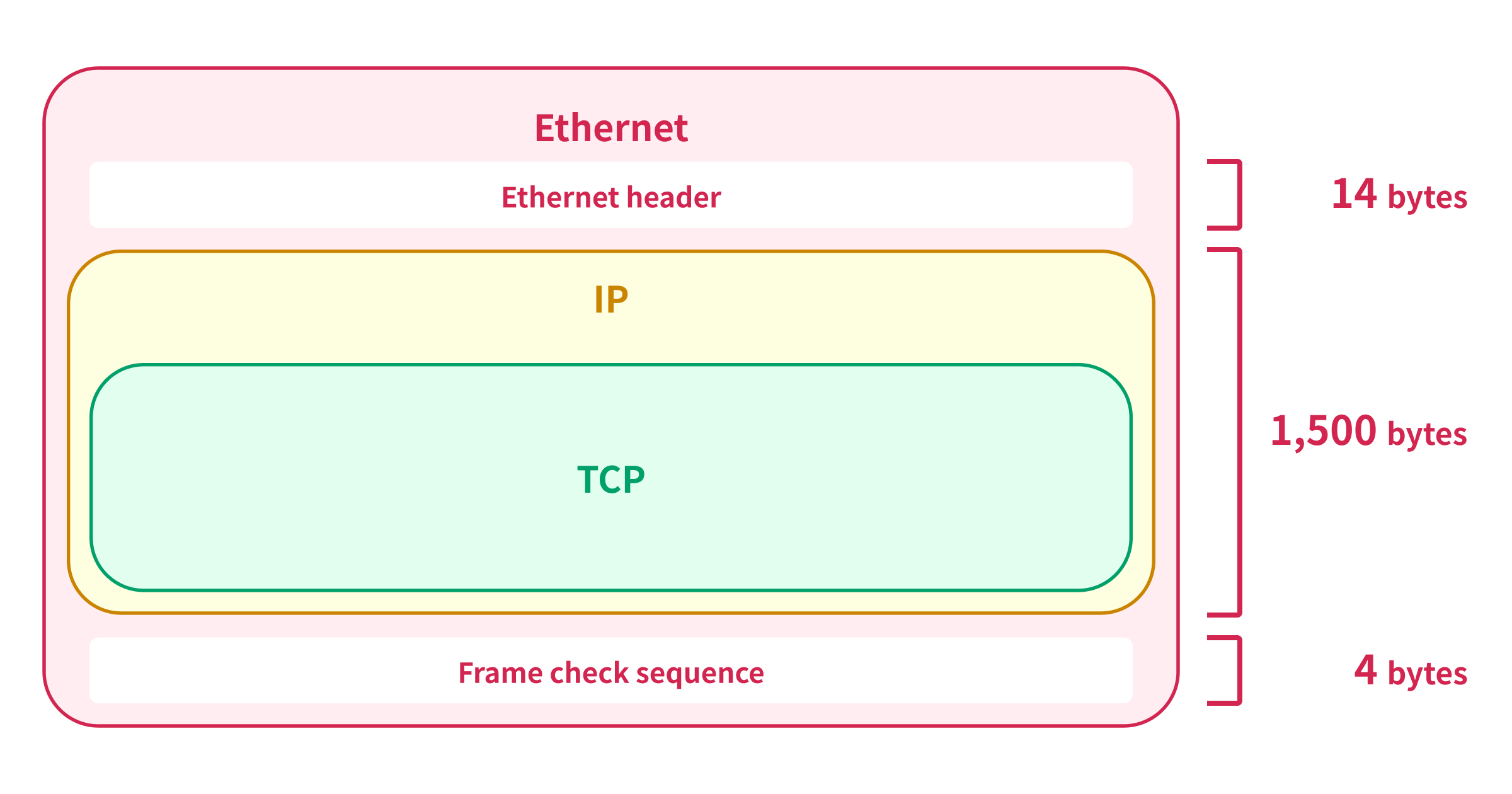
This is why James mentioned 1,500 bytes as a soft limit of the TCP. But, why the TCP allows the maximum size of 65,535 bytes for the TCP packet even though the IP packet has a limit of 1,500 bytes?
Actually, the IP packet supports fragmentation, as defined in the RFC 791.
https://datatracker.ietf.org/doc/html/rfc791
Fragmentation of an internet datagram is necessary when it
originates in a local net that allows a large packet size and must
traverse a local net that limits packets to a smaller size to reach
its destination.
When the IP packet is fragmented, the original IP packet is divided into multiple smaller IP packets, and each of the smaller IP packets is encapsulated in different Ethernet frames.
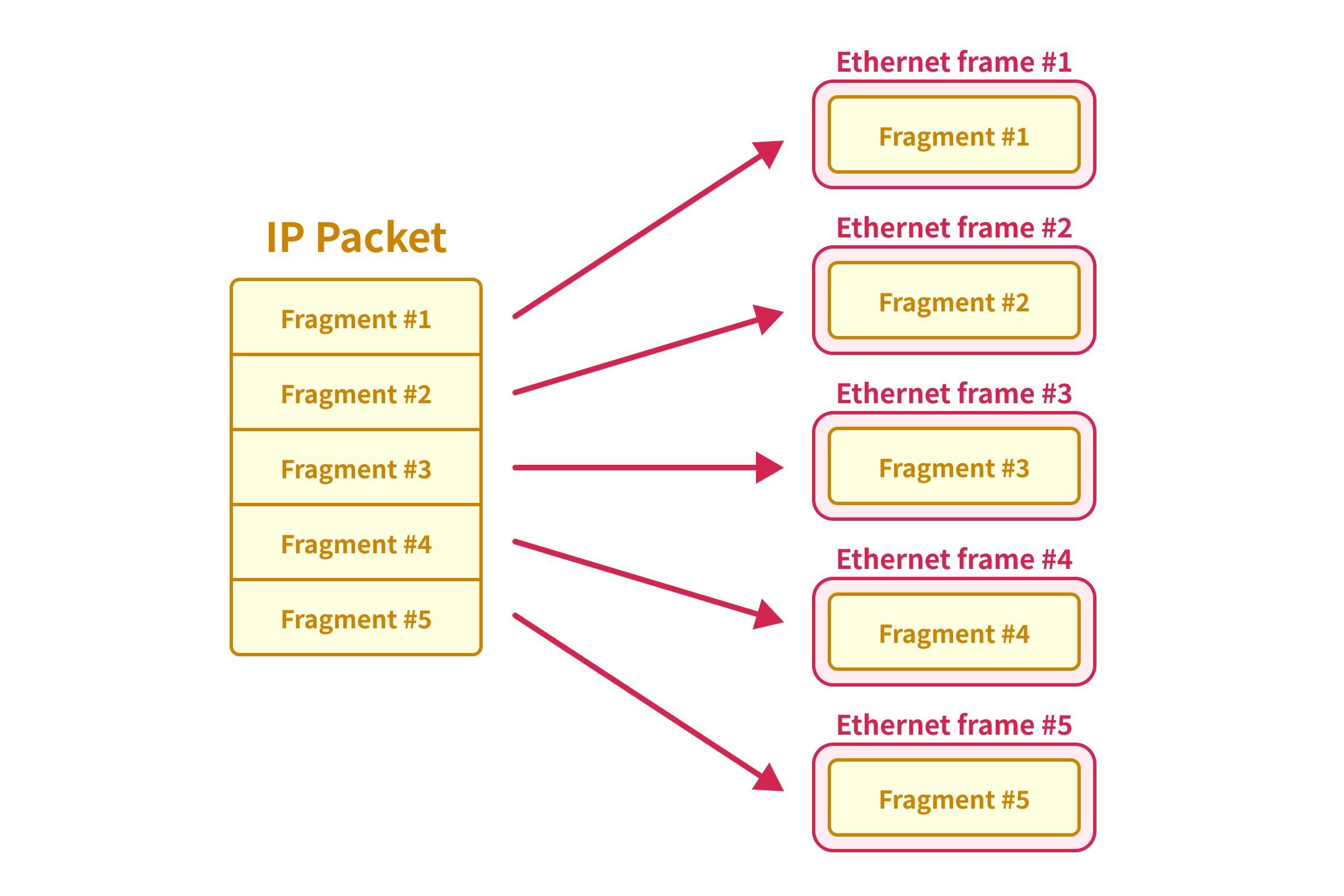
Since the fragmented IP packet won’t be passed to the TCP layer until all the fragments are received, we can synchronize a large TCP packet even if we split the TCP packet into multiple IP packets.
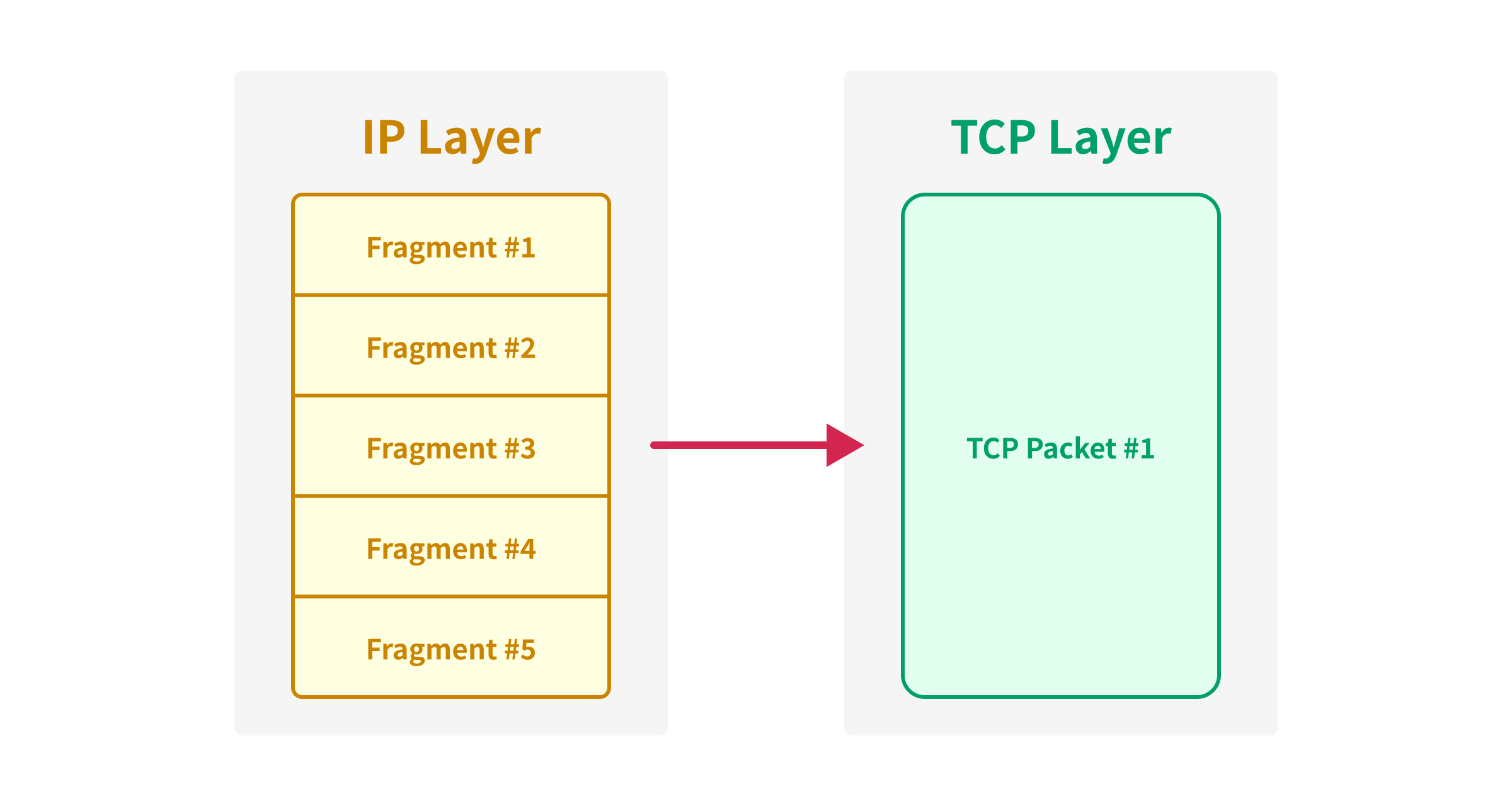
TCP and Sequence Number
We can now send a TCP packet up to 65,535 bytes2 by using IP fragmentation, but it’s still not enough when we want to send a large number of requests simultaneously.
Since we are now using the TCP window size fully, we can’t expand the limit further with a single TCP packet, so we need to figure out how to synchronize the multiple TCP packets.
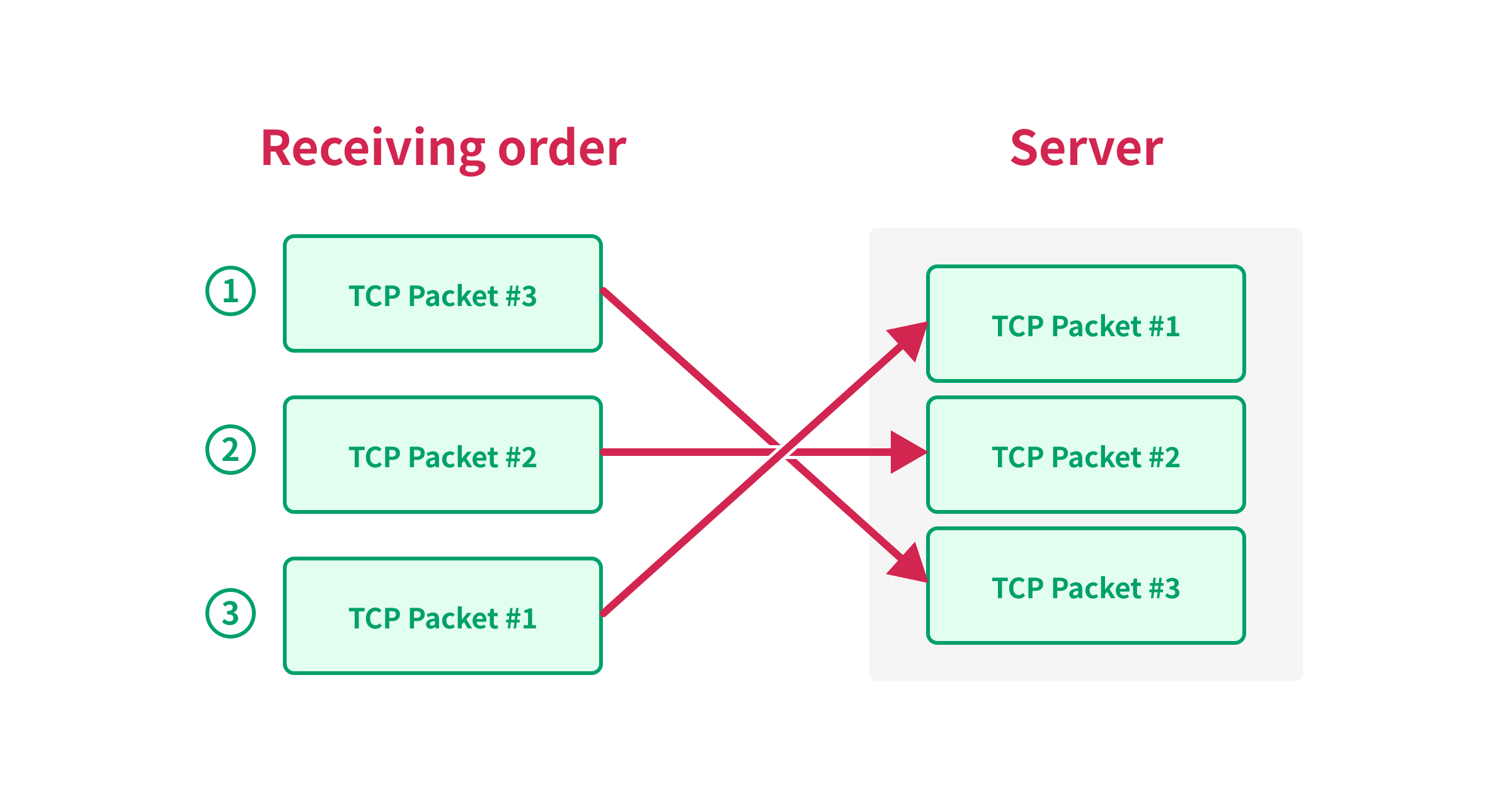
Fortunately for us, TCP guarantees the order of the packets via the sequence number.
When the target server receives the TCP packet, it checks the sequence number of the packet and reorders the packets based on the sequence number.
https://datatracker.ietf.org/doc/html/rfc9293#section-3.10-8
A natural way to think about processing incoming segments is to imagine that they are first tested for proper sequence number (i.e., that their contents lie in the range of the expected "receive window" in the sequence number space) and then that they are generally queued and processed in sequence number order.
First Sequence Sync
Since TCP guarantees the order of the packets, we can use the sequence number to synchronize the multiple TCP packets.
For example, let’s say we have the following TCP packets to send:
| Packet | Sequence Number |
|---|---|
| A | 1 |
| B | 2 |
| C | 3 |
If the server receives the packets in the order of B, C, and A, the server will not be able to process the packets until it receives packet A, because the server needs to process the packets in the order of the sequence number.
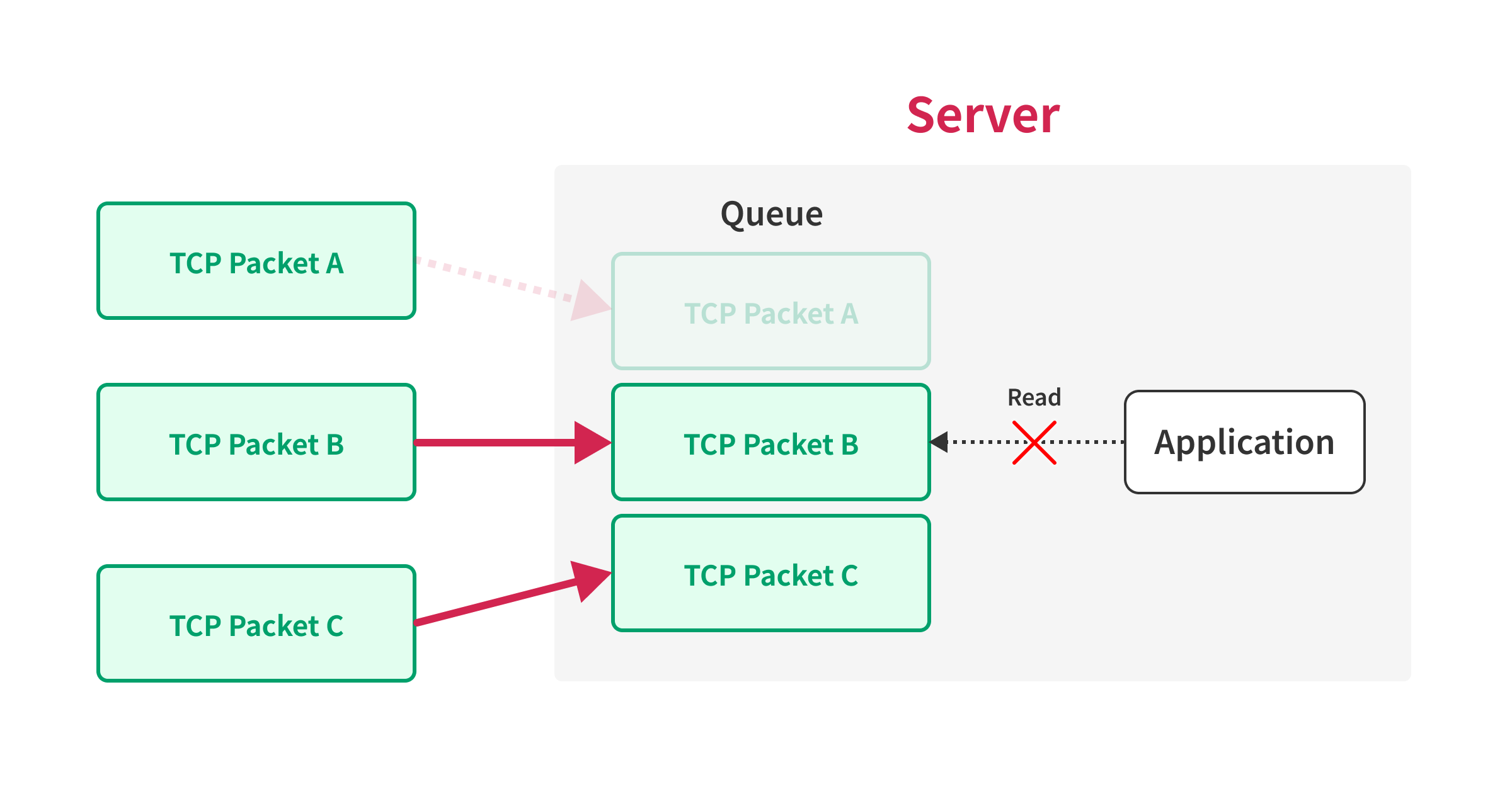
By using this behavior, we can prevent the server from processing the packets until we send the final packet, that contains the first sequence number.
So, we can force the server to process the packets simultaneously by sending the packet with the first sequence number last.
Combining IP fragmentation and First Sequence Sync
By using the IP fragmentation and the first sequence sync, we can now send a lot of large requests simultaneously without worrying about the request size.
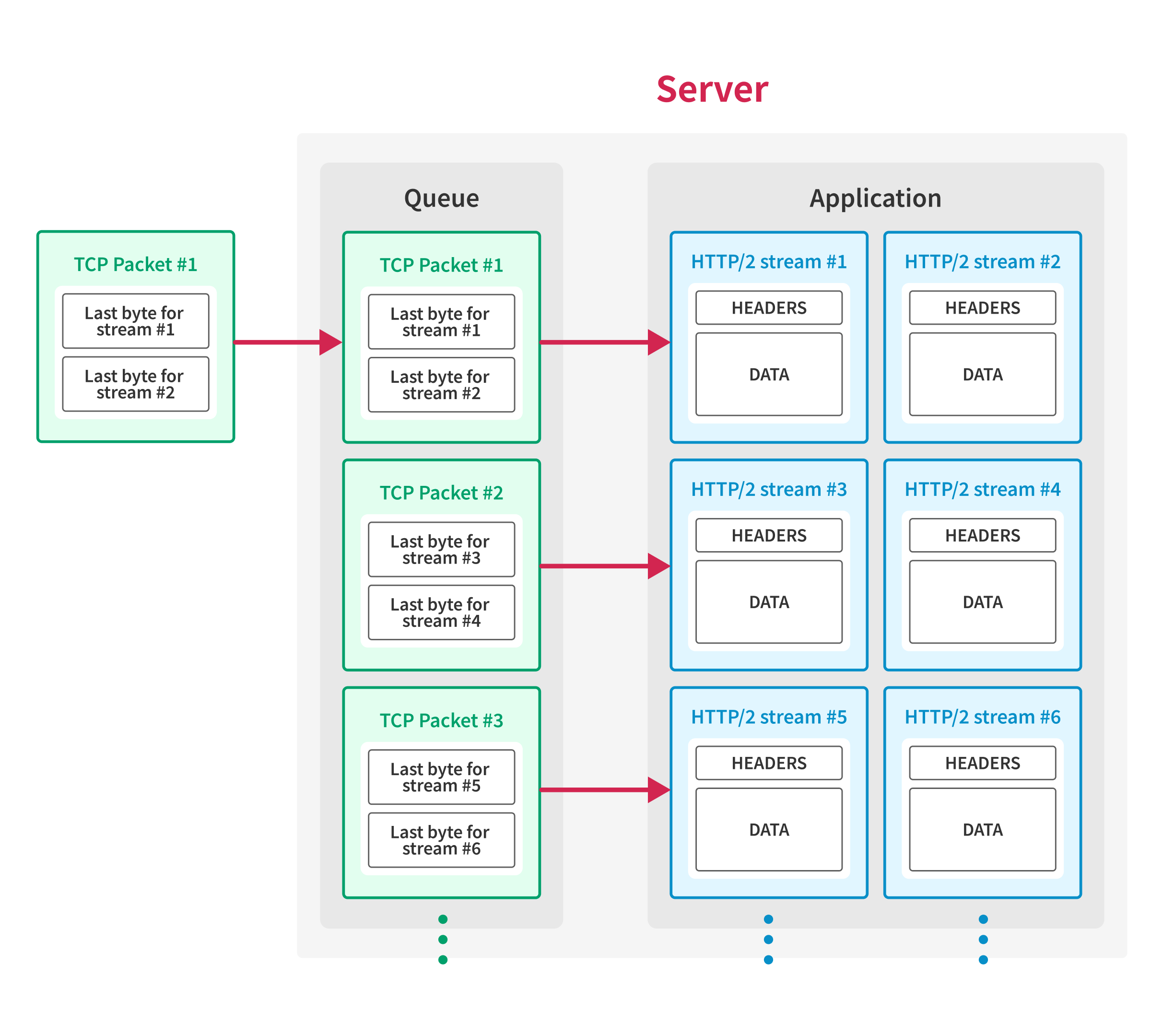
Below is the overview of the flow of the techniques:
First, the client establishes a TCP connection with the server and opens HTTP/2 streams, then sends request data except for the last byte of each request. At this point, the application waits for the client to send the remaining bytes of the requests, so requests are not processed yet.
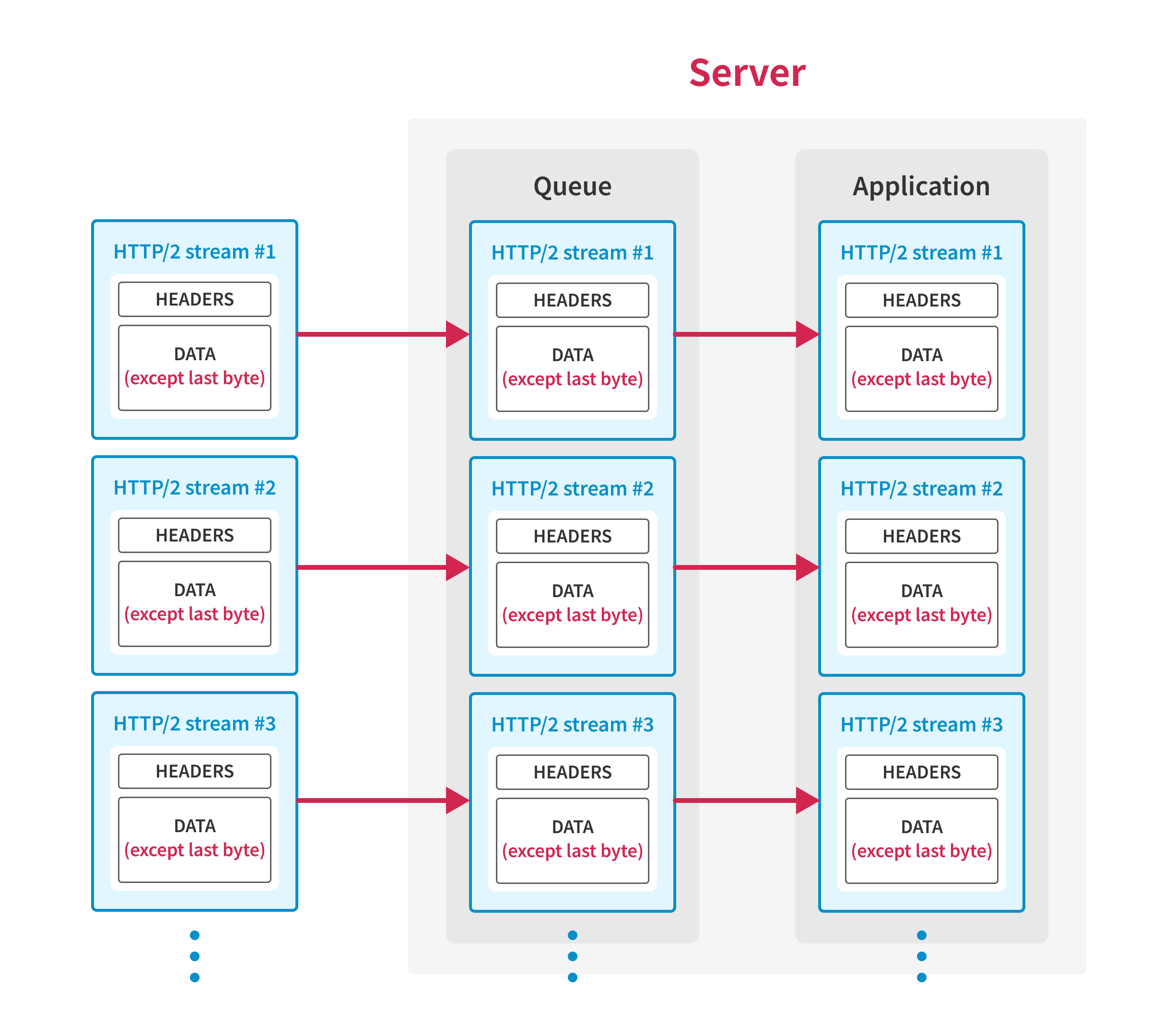
Then, the client creates large TCP packets that contain multiple HTTP/2 frames with the last byte of requests and sends the packets to the server using IP fragmentation3, except for the TCP packet with the first sequence number.
As the server receives the packets out-of-order, the server waits for the final packet before passing the packets to the application.
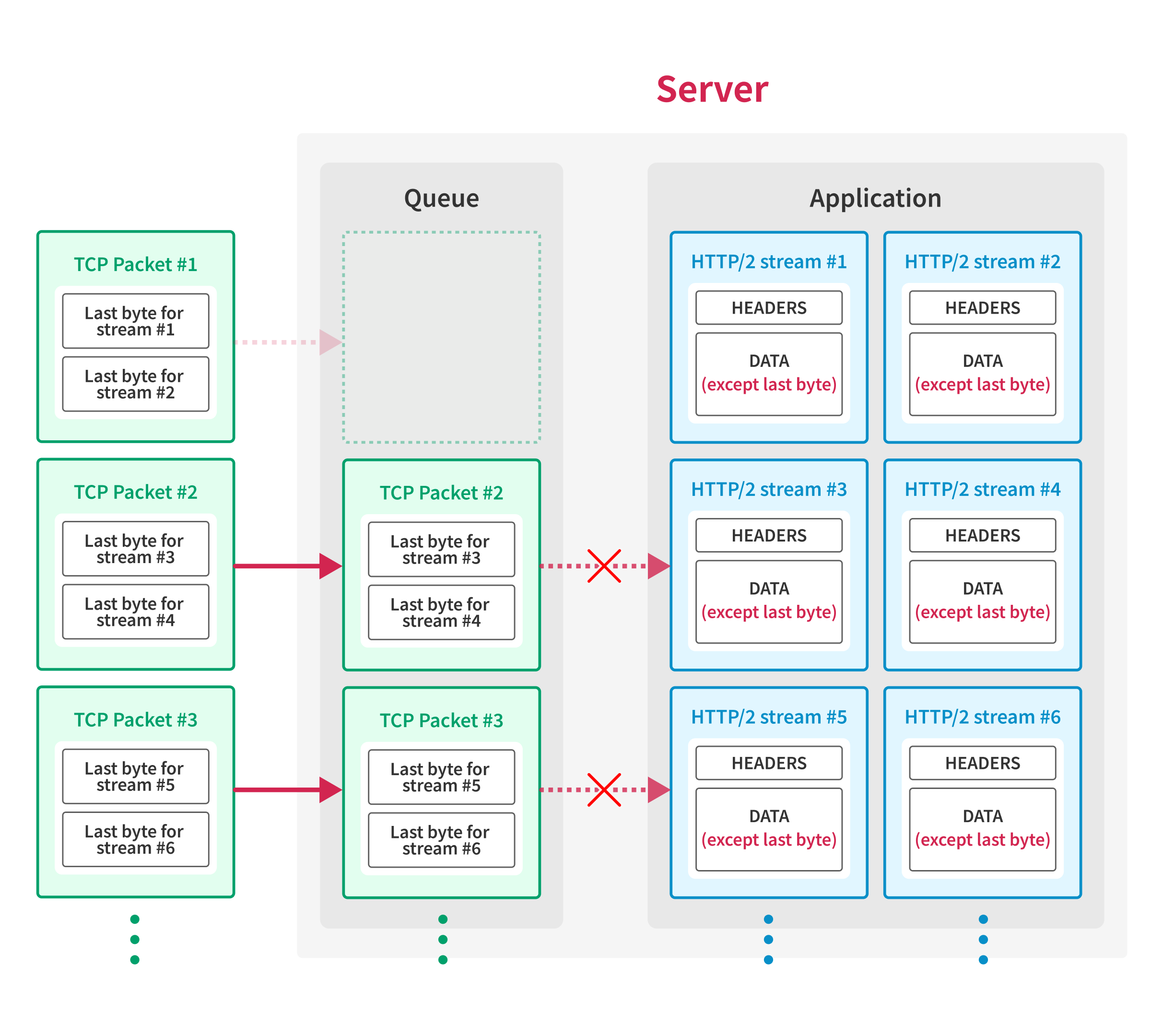
Finally, once the server receives all the packets sent above, the client sends the TCP packet with the first sequence number, and the server processes all the requests simultaneously.
Limiting factors
While the above technique seems to work well, several factors can affect the number of requests that can be sent simultaneously.
One obvious factor is the TCP buffer size of the server. Since the server needs to store the packets in the buffer until it reassembles the packets, the server needs to have a large enough buffer to store the packets that are sent out-of-order.
Thankfully, modern servers usually have a large RAM, and most OS-es have enough buffer to store the packets by default, so the buffer size is not a big issue in most cases.
However, there is another factor that can affect the number of requests that can be sent simultaneously.
In HTTP/2, the number of streams that can be opened simultaneously is limited by the SETTINGS_MAX_CONCURRENT_STREAMS setting.
For example, if the server has the SETTINGS_MAX_CONCURRENT_STREAMS set to 100, the server can process only 100 requests simultaneously in one TCP connection.
This is a critical issue when we try to use the techniques described in this article because we need to send the requests in one TCP connection to use the first sequence sync.4
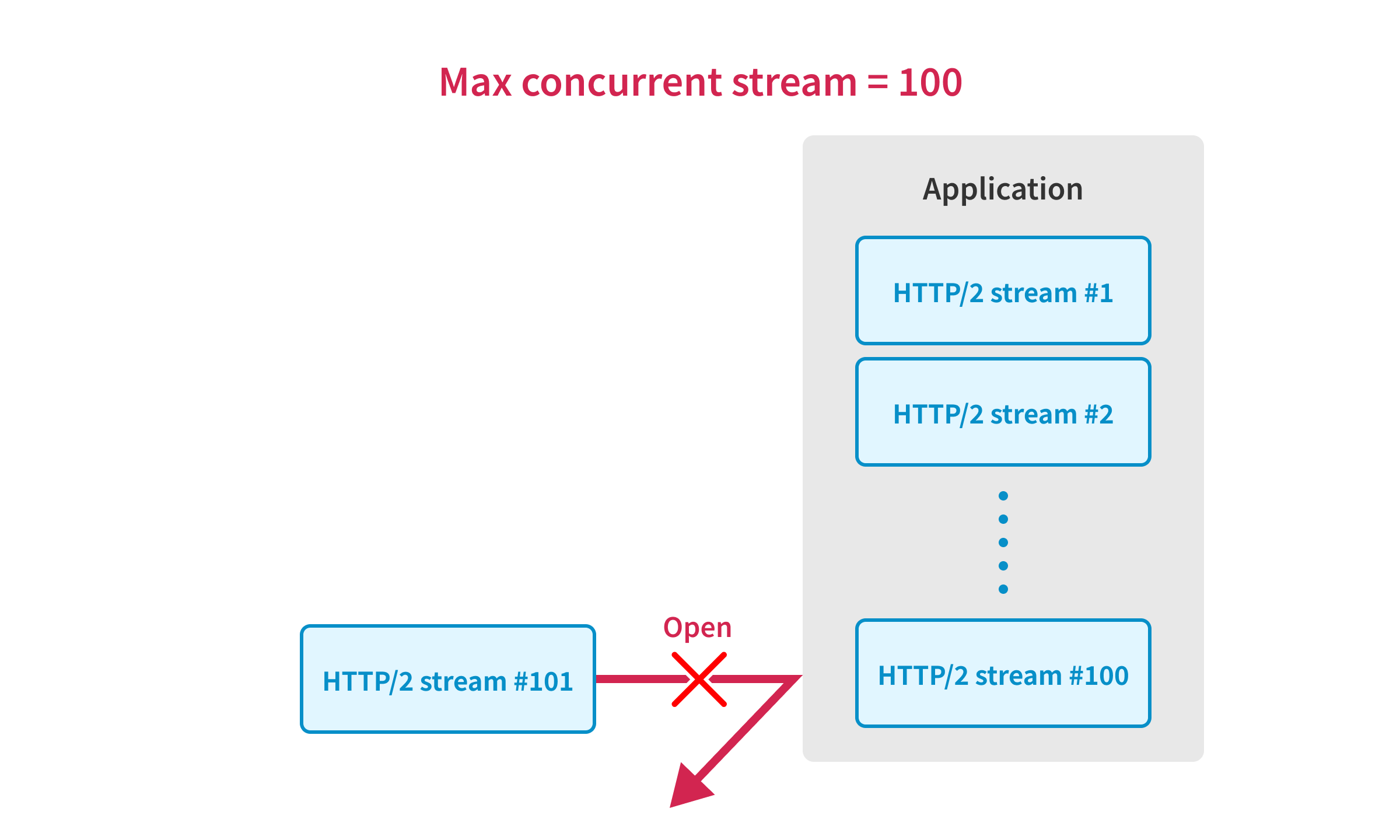
Unfortunately, popular HTTP servers like Apache and Nginx have a strict SETTINGS_MAX_CONCURRENT_STREAMS setting:
| Implementation | Default SETTINGS_MAX_CONCURRENT_STREAMS |
|---|---|
| Apache httpd | 100 |
| Nginx | 128 |
| Go | 250 |
That being said, RFC 9113 defines
the initial value of the SETTINGS_MAX_CONCURRENT_STREAMS as unlimited, and some implementation have a generous limit:
| Implementation | Default SETTINGS_MAX_CONCURRENT_STREAMS |
|---|---|
| nghttp2 | 4294967295 |
| Node.js | 4294967295 5 |
So, the techniques described in this article could be really powerful depending on the HTTP/2 implementation used by the server.
Demonstration
In this section, I will benchmark the performance of the first sequence sync, and demonstrate how the exploitation of the limit-overrun vulnerability with it looks like.
I’ve used the following environment for the demonstration:
| Server | Client | |
|---|---|---|
| Platform | AWS EC2 | AWS EC2 |
| OS | Amazon Linux 2023 | Amazon Linux 2023 |
| Kernel Version | 6.1.91 | 6.1.91 |
| Instance Type | c5a.4xlarge | t2.micro |
| Region | sa-east-1 | ap-northeast-1 |
These servers are located on almost the opposite side of the world, and the network latency between the servers is around 250ms.
I configured the iptables of the client machine to prevent the RST packet from being sent to the server:
iptables -A OUTPUT -p tcp --tcp-flags RST RST -s [IP] -j DROP
Firstly, I will synchronize the 10,000 requests using the first sequence sync, and measure the time it takes to send the requests.
The code that I used for the benchmark is available in the rc-benchmark
folder of the repository.6
Here is the result of the benchmark:
| Metrics | Value |
|---|---|
| Total time | 166460500ns |
| Average time between requests | 16647ns |
| Max time between requests | 553627ns |
| Median time between requests | 14221ns |
| Min time between requests | 220ns |
As you can see, I was able to send 10,000 requests in about 166ms.7 This is equivalent to 0.0166ms per request, which is significantly fast considering the network latency between the servers is around 250ms.
Next, I will demonstrate the exploitation of the limit-overrun vulnerability in the rate-limiting of the one-time token authentication.
The code that I used for this demonstration is available in the rc-pin-bypass
folder of the repository.8
While the target server software limits the maximum authentication attempts to 5 times, the client machine was able to perform 1,000 attempts, bypassing the rate limiting.
Considering that only about 10 attempts could be made when I tried the same attack with the last byte sync, this is a significantly more reliable and efficient attack.
Further Improvements
While the demonstration worked well, there are still some improvements that can be made to make the attack more reliable and efficient.
Some examples are the following:
- Support for HTTPS: The current PoC requires the support of HTTP/2 over the plaintext connection, which some implementations don’t support because the browser only supports HTTP/2 over TLS. By implementing the PoC with TLS support, we can apply these techniques to a wider range of targets.
- Support for the case where the target server updates the TCP window: The current implementation doesn’t support the case where the target server updates the TCP window while sending requests. With the current PoC, the attack will likely fail if the target server updates the TCP window.
- Integrate with the existing proxy tools: The current PoC doesn’t have flexibility, and requires changes to the code to add headers or modify the request body. By integrating with the existing proxy tools like Burp Suite or Caido, we can easily modify the request and headers.
- Please note that this might not be possible because these techniques rely on layers 3 and 4 of the OSI model and the proxy tools are designed to work on layer 7.
Conclusion
In this article, I explained the technique that I named First Sequence Sync to expand the limitation of the single packet attack.
These techniques could be really powerful depending on the HTTP/2 implementation used by the server and are useful when used to exploit the limit-overrun vulnerabilities that are hard to exploit with the traditional techniques.
While the technique could certainly benefit from further refinement, I already find it quite valuable for exploiting vulnerabilities that would otherwise be unexploitable. In fact, I successfully exploited the vulnerability introduced earlier, and I hope you can achieve similar success. Furthermore, I’m looking forward to seeing the new toolings implementing these techniques, too.
Shameless plug
At Flatt Security, we specialize in providing top-notch security assessment and penetration testing services. To celebrate the update of our brand new English web pages, you can currently receive a month-long investigation by our elite engineers for just $40,000!
We also offer a powerful security assessment tool called Shisho Cloud, which combines Cloud Security Posture Management (CSPM) and Cloud Infrastructure Entitlement Management (CIEM) capabilities with Dynamic Application Security Testing (DAST) for web applications.
If you’re interested in learning more, feel free to reach out to us at https://flatt.tech/en .
-
Jumbo frame is an exception here, but as it requires all the network devices between the sender and the receiver to support it, we will not consider it in this article. ↩︎
-
In fact, it depends on the TCP window size set by the server. Please note that the default maximum size of the TCP window size is 65,535 bytes, but RFC 7323 defines the Window Scale Option that allows the maximum size of the TCP window size to be 1 GiB. However, we can’t force the server to use the Window Scale Option, and my testing shows that test environments usually set the TCP window size to around 62,000 ~ 63,000 bytes. ↩︎
-
In theory, IP fragmentation shouldn’t be necessary because the client can send the packets out-of-order and synchronize packets as much as we want. However, when I tested the techniques without IP fragmentation, the attack became less reliable, so I’m mentioning IP fragmentation in this article. ↩︎
-
While it’s true that we can synchronize the requests without the last byte sync technique, the concurrency is still limited by the
SETTINGS_MAX_CONCURRENT_STREAMSsetting. ↩︎ -
Node.js uses nghttp2 internally, and it inherits the
SETTINGS_MAX_CONCURRENT_STREAMSsetting from nghttp2. ↩︎ -
Please note that I intentionally set the
MaxConcurrentStreamsto 10,000 for this demonstration as Go has 250 as the default value. As I mentioned earlier, the default value of theMaxConcurrentStreamsis implementation-dependent, and it’s not that unusual to see a large limit in the real world. ↩︎ -
Please note this solely depends on the performance of the target server. When I tested the same attack against the t2.micro instance, the attack took about 500ms to complete. ↩︎
-
This implementation uses 3 3-digit PIN for the one-time token to demonstrate the attack reliably. When I tested the attack with the 4-digit PIN with the same implementation, around 2,000 attempts could be made. So, the attack still works on the 4-digit PIN, but it wasn’t possible to cover the entire PIN space. ↩︎