
Why XSS Persists in This Frameworks Era?
Posted on July 8, 2025 • 24 minutes • 4968 words
Table of contents
- Introduction
- Data on the Frequency and Severity of XSS
-
Why XSS Still Occurs
- Premise 1: XSS Sinks Are Extremely Diverse
- Premise 2: Frameworks Only Address a Limited Set of Sinks
- Roadmap and Summary
- Why It Can’t Prevent HTML-Related XSS to Use Frameworks?
- Sinks That Exist Outside of a Framework’s Protection Scope
- XSS Caused by Library Misuse
- The Effectiveness of Multi-Layered Defense for XSS
- Recommended Countermeasures
Introduction
Hi, I’m canalun (@i_am_canalun ), a security researcher at GMO Flatt Security Inc.
This article explores the question: “Why Does XSS Still Occur So Frequently?” We will delve into why this notorious and classic vulnerability despite the widespread adoption of built-in XSS countermeasures in modern development frameworks.
The world of web development, especially frameworks, is evolving at a rapid pace, bringing improvements not only in development efficiency but also in security.
In particular, defensive mechanisms against XSS have become increasingly robust. Today, many frameworks automatically escape HTML content and attribute values. Also, interfaces that could lead to the dangerous use of innerHTML are given names that signal their risk (e.g., unsafeHTML in Lit, dangerouslySetInnerHTML in React). Recently, React v19 added the ability to disable javascript: scheme URLs1, and that means yet another attack vector for XSS is neutralized.
This progress might lead some developers to believe, “If I’m using a modern framework, I don’t need to worry about XSS.”
However, the reality is quite different. Even in this era of advanced frameworks, data shows that XSS remains one of the top vulnerabilities in terms of both severity and frequency. It sounds like a joke, but unfortunately, it’s the reality.
Data on the Frequency and Severity of XSS
Let’s examine three data sources that demonstrate how XSS remains a severe and frequent vulnerability.
CWE Top 25 Archive
The MITRE Corporation, a U.S. non-profit organization, manages global vulnerabilities through CVE (Common Vulnerabilities and Exposures) and categorizes them using CWE (Common Weakness Enumeration). For example, SQL Injection is CWE-89, and XSS is CWE-79.
The “CWE Top 25 Archive” is an annual report that ranks the most dangerous software weaknesses by score including both severity and prevalence. The table below shows the top three weaknesses from the last five years.
| 20202 | 20213 | 20224 | 20235 | 20246 | |
|---|---|---|---|---|---|
| Rank 1 | XSS | Out-of-bounds Write | Out-of-bounds Write | Out-of-bounds Write | XSS |
| Rank 2 | Out-of-bounds Write | XSS | XSS | XSS | Out-of-bounds Write |
| Rank 3 | Improper Input Validation | Out-of-bounds Read | SQLi | SQLi | SQLi |
As the table shows, XSS has consistently ranked first or second over the past five years, underscoring its status as a top-tier vulnerability!
Vulnerability Reports by Industry on HackerOne
Next, let’s look at industry-specific data from the “8th Annual Hacker-Powered Security Report 2024/2025”7, published by one of the most famous bug bounty platforms, HackerOne. The graph below shows statistics for the top 10 reported vulnerabilities from 2023 to 2024, broken down by industry. The graph is original.
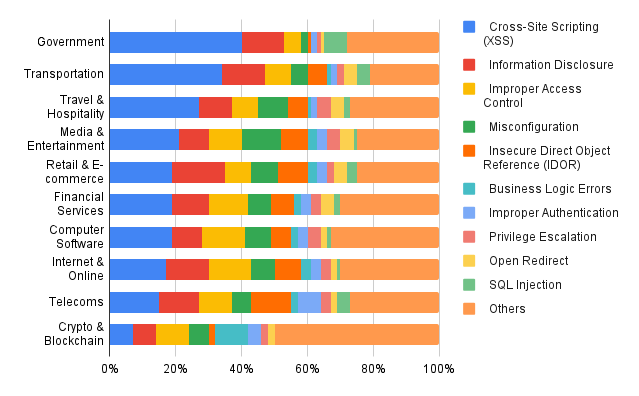
This data reveals that XSS accounts for approximately 20% of reported vulnerabilities in all industries except for Crypto. This suggests that XSS is a universal challenge, affecting everything from government agencies to e-commerce.
Vulnerability Detection Trends at GMO Flatt Security
Finally, we’ll share trends from our own vulnerability assessment data at GMO Flatt Security8. When we categorized the vulnerabilities we discovered in 2023 by volume, XSS was the third most common, following authentication/authorization flaws and business logic vulnerabilities.
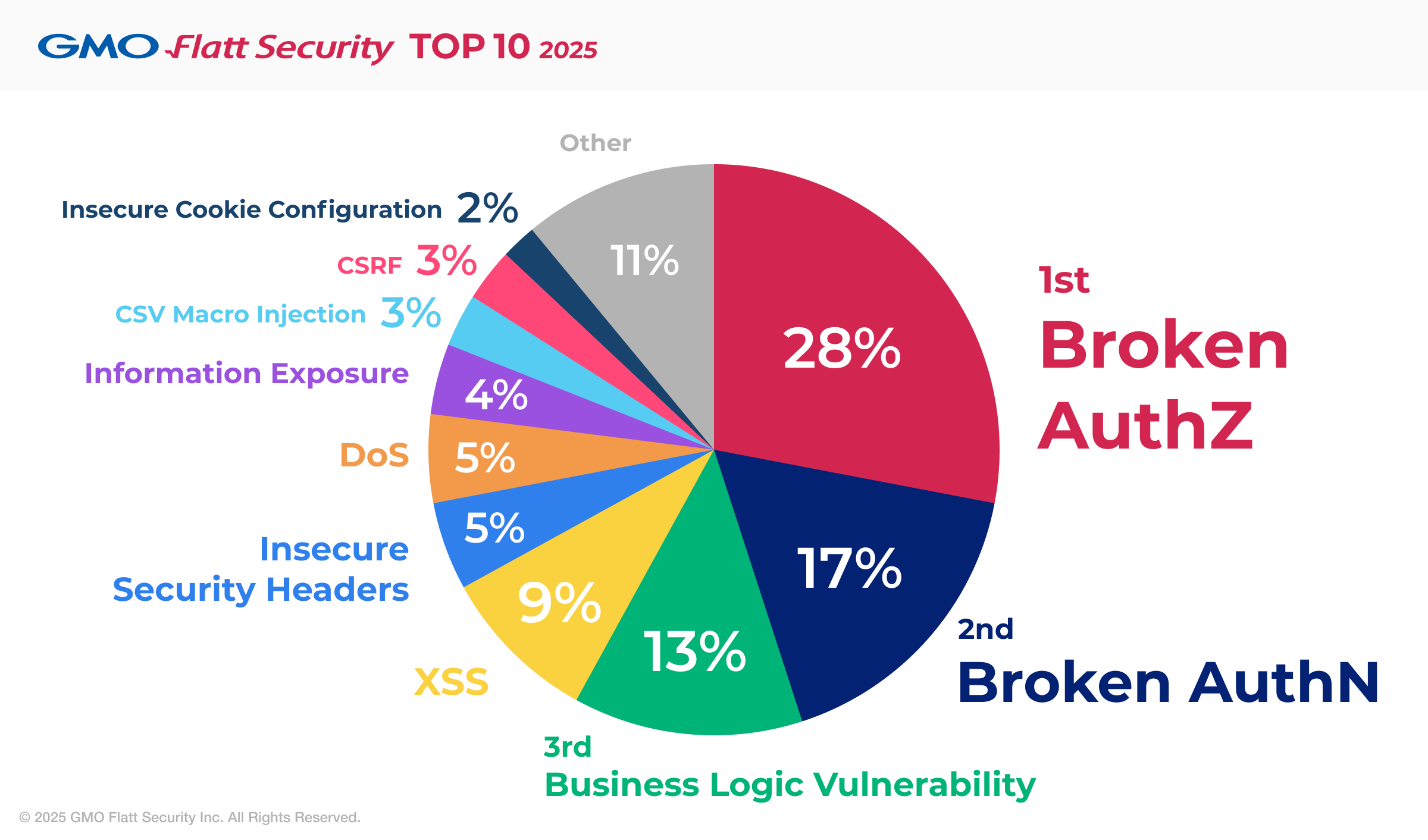
While this data reflects the prevalence of B2B SaaS applications among our clients, leading to a high number of authentication-related findings, XSS still outpaces other common vulnerabilities like CSRF and misconfigured security headers.
These three data sources indicate that XSS remains a consistently discovered vulnerability with significant severity still today.
Why XSS Still Occurs
Now, we will address the central question: “Why does XSS still happen in the modern era?” We’ll explore the technical reasons behind these numbers.
Premise 1: XSS Sinks Are Extremely Diverse
Two important concepts for understanding vulnerabilities are “sources” and “sinks”. A source is an entry point for attacker-controllable data (e.g., a form, a filename), while a sink is a location in the program where that data ends up and causes a vulnerability (e.g., embedding in HTML, execution as JavaScript).
For example, a typical sink of SQL injection is raw query generation such as db.query("SELECT * FROM users WHERE name = '" + userInput + "'");. For path traversal, it’s like readFile("/user/uploads/" + userInput);.
XSS sinks are incredibly diverse, leading to vulnerabilities in various contexts. Here are some representative sink patterns:
- HTML: Inserting untrusted data as HTML.
- Example:
document.getElementById('output').innerHTML = [userInput];(XSS occurs ifuserInputis<img src onerror=alert(document.domain)>)
- Example:
- HTML Attribute (non-URL): Inserting untrusted data as an HTML attribute value.
- Example:
<button type="text" data-value="[userInput]">(XSS occurs ifuserInputis"><script>alert(document.domain)<p ")
- Example:
- HTML Attribute (URL): Using untrusted data as a URL in an HTML attribute.
- Example:
<a href=[userInput]>(XSS occurs ifuserInputisjavascript:alert(document.domain))
- Example:
- JavaScript (URL): Using untrusted data as a URL within JavaScript code.
- Example:
window.location.href = [userInput];(XSS occurs ifuserInputisjavascript:alert(document.domain))
- Example:
- JavaScript (Function Construction): Using untrusted data to construct a JavaScript function.
- Example:
eval('var data = "' + userInput + '";');(XSS occurs ifuserInputis";alert(document.domain);//)
- Example:
Premise 2: Frameworks Only Address a Limited Set of Sinks
The XSS countermeasures provided by most web frameworks primarily focus on escaping HTML output. This is intended to prevent data from being unintentionally interpreted as HTML or JavaScript.
In other words, these features mainly target the “HTML” and “HTML Attribute (non-URL)” sinks. So, “HTML Attribute (URL)” and other JavaScript-related sinks are often not covered by a framework’s standard protection.
Roadmap and Summary
Based on these premises, we will detail the causes of XSS from two perspectives.
The first question is: why can’t HTML-related XSS (i.e., “HTML” and “HTML Attribute (non-URL)”) be fully prevented even with a framework’s built-in escaping mechanisms? Yes, this type of XSS can happen even under frameworks.
The second question is: in what scenarios do other sinks (i.e., “HTML Attribute (URL)” and JavaScript related ones) appear? Some of you may think like “When do we have to set URL to href?”
We will explore these two questions with concrete examples from real-world reports on HackerOne :) Specifically, we take some interesting cases from those reported in 2024 on HackerOne and given CWE of XSS. If you’d like to get the raw result of categorizing those reports by cause, you can refer this repository: https://github.com/canalun/h1-2024-xss-categorization
Well, before jumping into detailed analysis, here is the summary of the modern XSS patterns.
- Data that was assumed to be safe was, in fact, not.
- A custom sanitizer was bypassed, or an open-source sanitizer was used incorrectly.
- The framework’s built-in defense mechanisms were not used correctly or were intentionally avoided.
- The implementation contained a sink that was outside the framework’s protection scope and not widely recognized.
- A library’s specifications were misunderstood, leading to incorrect usage.
Why It Can’t Prevent HTML-Related XSS to Use Frameworks?
First, let’s explore why XSS targeting “HTML” and “HTML Attribute (non-URL)” sinks still occurs, even with framework-level HTML escaping. This can be broken down into two main factors.
A. Cases Where Framework Escaping Mechanisms Cannot Be Used
When developing a somewhat complex system or one that integrates various modules, you’ll encounter cases where it’s overwhelmingly better, or even necessary, to set HTML directly without using the framework’s escaping mechanism. For example, code that exists outside of the framework cannot use its escaping features. In other cases, while you could technically parse the provided HTML and fit it into JSX to escape it, doing so is often unrealistic from a development cost perspective.
This is the first point: there are situations where the framework’s escaping mechanism is simply unavailable.
This issue often arises when incorporating modules that output HTML, such as a WYSIWYG editor or a Markdown parser. If you’re using a trusted CMS, you might implement a feature that directly inserts the HTML fetched from it. You might also encounter mechanisms that are difficult for frameworks to handle, like cross-frame communication.
Now, I imagine you’re all thinking:
“I know that directly inserting HTML is dangerous! When I absolutely have to do it, I’ll make sure the input is safe or run it through a sanitizer!”
And that’s exactly the point. The core of this issue is whether you can truly get by with just verifying input safety or using a sanitizer. Let’s explore that.
A-1. Errors in Determining Data Safety
Now, let’s first discuss the act of verifying that an input is safe. In the paper “Securing the Tangled Web”9, authored by Google engineer Christoph Kern, mistakes in this very verification process are cited as one of the primary causes of Cross-Site Scripting (XSS).
In this paper, the author examines the causes of XSS based on real-world cases, specifically, XSS reported through the Google VRP10. It argues that verifying the safety of values in web applications is extremely difficult. The main reasons cited are as follows11:
-
User inputs and fetched data from various sources are combined through complex conditional branches before being used.
-
The source code is constantly changing over time.
An interesting related topic mentioned is the issue of responsibility. Bugs can also arise from a failure to correctly establish whether the front-end or the back-end is responsible for ensuring the safety of a value.
This bug could arise in practice from a misunderstanding between front-end and back-end developers regarding responsibilities for data validation and sanitization.
Let’s see a HackerOne example, CVE-2021-20323 . It was of U.S. Dept. of Defense and triggered by the below payload.
{"<img onerror=confirm('xss_poc_unexpectedbufferc0n') src/>":1}
As the payload suggests, a JSON key (field name) was interpreted as HTML, causing XSS. It’s plausible the developers who really care about handling values may have incorrectly assumed keys are safe to render.
A-2. Bypassing Custom Sanitizers
Now, let’s turn our attention to sanitizers. If direct insertion is unavoidable and the input values cannot be trusted, what about sanitizing them?
First, regarding custom-built sanitizers, if you asked 100 security engineers whether they would recommend it, 100 of them would likely tell you to stop. That’s because HTML sanitizers have flaws in nine cases out of ten.
Let’s look at a real-world example. In HackerOne report #1675516
, a vulnerability in a sanitizer was exploited. Specifically, the attacker managed to bypass the sanitizer by following multiple unclosed <p> tags with an <audio> tag that used a slash as a delimiter for the tag and attribute names. Here is the actual payload:
<p><p><p><p><p><p><p><p><audio/src/onerror=alert(document.domain)>.
This payload illustrates the difficulty of creating an HTML sanitizer that is both reasonably tolerant and correctly neutralizes threats.
In the first place, this payload is clearly not what we would consider “correct” HTML. The <p> tags are not closed, and there is no space between the tag name and the attribute name in the <audio> tag. Nevertheless, when a browser is given the above value as HTML, it interprets it “as best it can”, creating eight <p> elements and one <audio> element, and then triggers the popup12. Examples like this, where a browser will “make sense” of “incorrect” HTML, are endless. The famous post “How browsers work” by Tali and Paul includes this fantastic passage13:
You never get an “Invalid Syntax” error on an HTML page. Browsers fix any invalid content and go on.
Furthermore, even if you exclude such obviously “incorrect” HTML, sanitization remains difficult. For example, the following is an example cited in the aforementioned Google paper to explain just how delicate a problem sanitization is. This Closure script escaping HTML and JS is incorrect, but if you were the code reviewer, would you be able to spot it?14
var escapedCat = goog.string.htmlEscape(category);
var jsEscapedCat = goog.string.escapeString(escapedCat);
catElem.innerHTML = `<a onclick="createCategoryList('` + jsEscapedCat + `')">` + escapedCat + `</a>`;
Under these circumstances, pursuing flexibility and high functionality with a self-made sanitizer is extremely dangerous. It’s far better to keep the implementation extremely simple and severely limit the allowed HTML formats. However, even with that approach, it’s still possible for a gap to be exploited and bypassed. For example, even if you only allow the <div> tag, the moment you allow attributes, the application gets vulnerable. An attacker will just set a malicious script as an onmouseenter attribute on the <div> tag. Or oncontentvisibilityautostatechange15?
Of course, if you restrict the tags and attributes much, much more, it’s theoretically possible to achieve safety. But at that point, I feel it’s worth reconsidering whether your implementation accepting HTML is truly necessary in the first place.
A-3. Misuse of Open-Source Sanitizers
So, when sanitization is necessary, you should use a widely used and trusted open-source library. For example, OWASP recommends DOMPurify16.
OWASP recommends DOMPurify for HTML Sanitization.
However, even the best sanitizers are ineffective if used incorrectly.
A common pattern known as “desanitization” means modifying or using wrongly the output of a sanitizer and introducing vulnerabilities as a result17. OWASP also warns about this risk18.
If you sanitize content and then modify it afterwards, you can easily void your security efforts. If you sanitize content and then send it to a library for use, check that it doesn’t mutate that string somehow. Otherwise, again, your security efforts are void.
You can see a well summarized examples on a Sonar’s report19. Let’s pick up some and the first is as below.
// (1) sanitize
data = DOMPurify.sanitize(userInput);
// (2) modify
data = data.replace(/class=".*?"/, 'class="custom-class" ');
// (3) use
document.body.innerHTML = data;
So, where is the vulnerability? The HTML should be safe after passing through DOMPurify.
However, as Sonar states in their article, the very belief that sanitized data is permanently safe for any subsequent modification or use is a dangerous misconception. As proof, this code can lead to XSS if userInput is class=" <div id="<img src onerror=alert(1)>">.
userInput = 'class=" <div id="<img src onerror=alert(1)>">';
// (1) sanitize
data = DOMPurify.sanitize(userInput);
// class=" <div id="<img src onerror=alert(1)>"></div>
// (2) modify
data = data.replace(/class=".*?"/, 'class="custom-class" ');
// class="custom-class"<img src onerror=alert(1)>"></div>
// (3) use
document.body.innerHTML = data; // triggers alert(1)
Furthermore, even if you don’t modify the data directly, some of you might be using sanitized HTML by embedding it within other HTML. This can also lead to XSS in some cases20.
B. Cases Where Framework Escaping Mechanisms Are Not Used Even Though Can Be Used
In the first half, we looked at cases where “the framework’s escaping mechanism is unavailable”.
Well, are we safe in situations where the escaping mechanism can be used? Unfortunately, that’s not always the case. For example, there are instances where a framework’s protective features are limited, or where developers use them incorrectly.
As a prerequisite, remember that XSS sinks are diverse. In reality, each type of sink requires a different kind of escaping21. For instance, a URL requires URL-specific escaping, while an HTML attribute needs a different kind of escaping. It’s fine if you’re using a framework like React that automatically applies the correct processing in the right place, but when the developer has to select and apply the appropriate escaping method, it’s not a simple task.
Furthermore, if the escaping mechanism is built into the framework’s syntax like in React (where you just need to put it in {}), there’s little risk of forgetting. Otherwise, mistakes can happen. For example, jQuery requires using the text() method to treat HTML as text, but a report on HackerOne #243363
appears to show a case where this call was forgotten, or a different, incorrect escaping method was chosen.
// note by author: XSS can be achieved by `msg`.
$(document).ready(function () {
const msg = window.location.search.match(/[&?]msg=([^&]+)/);
const msgText = msg ? decodeURIComponent(msg[1]) : "No data collected for this metric, cannot generate analytics.";
$(document.body).html(Utils.infoMessage(msgText));
});
Moreover, even when a framework’s features are easy to use, escape might be intentionally omitted due to implementation effort or time constraints, or approved with a “this should be fine” attitude. For instance, consider a case where complex JSON must be processed before it can be properly fitted into JSX, and a developer skips that tedious processing. The rendering of complex dynamic forms is a typical example of these cases.
Underlying such omissions and approvals is the judgment that “this input is probably safe”. But, as mentioned earlier with the Google paper, this judgment is, unfortunately, very often wrong. While I cannot disclose details, such cases have actually been discovered during our company’s security assessments.
To summarize, there are mistakes and decisions that lead to framework defense mechanisms being used improperly or not at all. This is a problem that can occur in various situations, such as during a transition to new technology when developers are unfamiliar with a framework, during the early and rushed stages of development, or in development situations constrained by a lack of time.
Sinks That Exist Outside of a Framework’s Protection Scope
Next, let’s discuss sinks that are often not protected by framework. They are less likely to be recognized as XSS risks, although these sinks appear in common development scenarios.
HTML Attribute (URL)
This is the case of using untrusted data as a URL in an HTML attribute value. For example, <a href="${userInput}">Link</a> is a straightforward case where if a URL with javascript: is put into userInput, a script will be triggered when the <a> tag is clicked.
Implementations like this are prone to appear in the following situations.
- When you’d like to set the
hrefof<a>orsrcof<img>based on a value received viapostMessageor other communication mechanisms. An example is to use an image selected within a popup window in the original tab. The following is vulnerable code actually reported in HackerOne report #1379400 .
Meteor.startup(function() {
MessageTypes.registerType({
id: 'message_snippeted',
system: true,
message: 'Snippeted_a_message',
data(message) {
const snippetLink = `<a href="/snippet/${ message.snippetId }/${ encodeURIComponent(message.snippetName) }">${ escapeHTML(message.snippetName) }</a>`;
return { snippetLink };
},
});
});
- Though it may be rare, standard spec sometimes says that a URL must be set as an attribute value. HackerOne report #2515808
is really interesting, because the vulnerability arose while implementing a flow defined by the “OAuth2 form post response mode” specification, which involves setting a URL in
actionattribute of<form>. It’s more of an HTML injection than XSS, though.
JavaScript (URL)
This involves using an untrusted URL with JavaScript APIs like window.open() or location.href. If a javascript: scheme URL is passed, a script is executed.
This pattern is frequently found in the two.
Especially, automatic redirection after login is dangerous because it’s typically done with an authorized session.
JavaScript (Function Construction)
This is the case of dynamically constructing and executing a script from untrusted data. For example, eval(userInput);.
You might be thinking, “Does that pattern even exist these days?”, but real-world examples do exist. HackerOne report #2670521
is a case where XSS was triggered when the value '};alert('XSS');var x={y:' was submitted through a form. Although the details haven’t been disclosed, it’s likely that the application was generating and executing a script from a search query string entered by the user.
Supplement: Frameworks That Do Validate URLs
I hope you now see that these sinks, which frameworks tend to overlook, often appear when implementing “common” features. This can be considered another reason why XSS continues to be a problem today, even with the widespread use of frameworks.
However, to say that frameworks completely ignore these sinks would also be incorrect. For example, the isUrl function, a standard validator used in frameworks like Laravel, rejects javascript: scheme22. Additionally, React v19 has finally handled javascript: scheme in the href attribute23 and XSS via <object>24.
Nevertheless, protection for these sinks is often weaker compared to the HTML-related sinks mentioned earlier. I feel that caution is still required.
XSS Caused by Library Misuse
Another point that’s often overlooked is XSS arising from the incorrect use of libraries. This isn’t about vulnerabilities in the libraries themselves that Dependabot would alert you to. Rather, it’s the perspective that XSS can be created by not correctly understanding a library’s specifications and misusing it.
For example, there’s a common pattern where a value set as the content property in a tooltip library is interpreted as HTML. The HTML output by markdown libraries also requires caution.
However, on this point, recent libraries have incorporated measures to prevent such misuse. For instance, the tooltip library “Tippy.js” controls this with an allowHTML option25, and the markdown parser “marked” includes a very prominent warning in its README26.
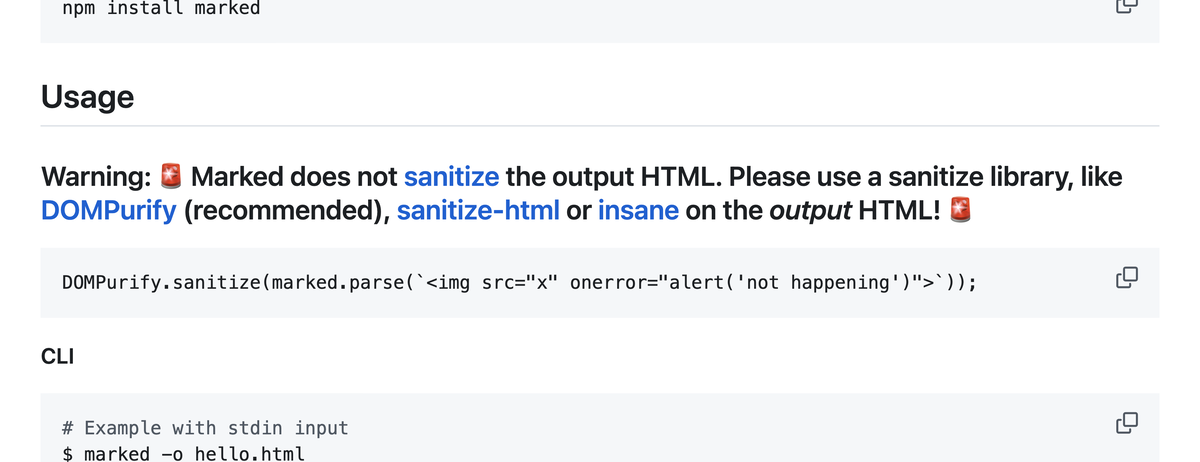
Still, I feel it wouldn’t be surprising to find libraries with dangerous interfaces that are exposed without much fanfare, and I believe it’s best to be careful with patterns that have low visibility, such as the difference between <%= (with HTML escaping) and <%- (without HTML escaping) in EJS syntax.
The Effectiveness of Multi-Layered Defense for XSS
Now, up to this point, we’ve looked at very specific, individual causes of XSS. Here, allow me to discuss something with a slightly different flavor: the effectiveness of multi-layered XSS defenses like CSP and WAFs.
To state the conclusion first, while it’s great to utilize these as additional security layers, it’s dangerous to think “we have CSP and WAF, so we’re safe for now” without taking a fundamental approach to the root causes we’ve discussed so far.
First, let’s look at CSP (Content Security Policy). As you may know, it’s said to be quite difficult to configure correctly. It’s so difficult that the CSP Level 3 specification itself states, “Deployment of an effective CSP against XSS is a challenge”27. In fact, numerous bypasses for host-based CSP policies have been discovered, including research about “script gadgets”28. For example, in the HackerOne report #2279346
, because scripts from https://www.google.com/recaptcha/ were permitted by the CSP, a CSP bypass was successfully executed by utilizing an Angular mechanism included in reCAPTCHA. Additionally, in #2246576
, although the details are unknown, a CSP bypass was performed on GitHub Enterprise Server.
In response to this, Strict CSP was proposed. In short, it’s a configuration method that says, “it’s sure that CSP tends to get bypassed, but if you set it up this way, it should be fine!”. It is defined in the CSP Level 3 specification
, and web.dev also provides guidance on how to implement it
. The idea behind Strict CSP is to control scripts using dynamic random values or hash values instead of hosts. This configuration can certainly reduce XSS risk significantly. On the other hand, there is the problem of high implementation costs. In fact, according to the 2024 Web Almanac published by the HTTP Archive, 91% of desktop sites and 92% of mobile sites using CSP still include unsafe-inline in their script-src directive29.
Considering these implementation difficulties and the actual situation, it doesn’t seem achievable to prevent XSS with CSP alone.
So, what about Trusted Types? This is a mechanism that forces input values for APIs that can become XSS sinks to have passed a validation defined by the page’s developer. The primary disadvantage is that it can only be used in Chromium-based browsers, meaning Firefox and Safari do not support it. Additionally, bypasses for this are also being researched. The repository “Cursed Types” collects XSS sinks that can slip through Trusted Types. The following pattern is an easy-to-understand example from the repo. XSS sinks are so diverse, aren’t they?
let attackerControlledString = '<img src=x onerror=alert(origin)>';
const blob = new Blob([attackerControlledString], {type: 'text/html'});
const url = URL.createObjectURL(blob);
location.href = url;
What about WAF? Yes, the situation is the same. There are many bypasses. It’s gotten to the point where even OWASP is sounding the alarm30.
WAF’s are unreliable and new bypass techniques are being discovered regularly. WAFs also don’t address the root cause of an XSS vulnerability. In addition, WAFs also miss a class of XSS vulnerabilities that operate exclusively client-side. WAFs are not recommended for preventing XSS, especially DOM-Based XSS.
So far, we’ve looked at CSP, Trusted Types, and WAF. It seems none of them can prevent XSS on their own.
The important thing to understand is that all multi-layered defense measures for XSS only serve to reduce the risk of XSS. In other words, they don’t fundamentally eliminate the source code that leads to XSS; they only increase the difficulty for an attacker to succeed when such source code exists.
Now, if you were an attacker who found a chance for XSS, would you give up just because the difficulty is high? You probably wouldn’t; you would definitely look for a bypass. And why wouldn’t you? There are malicious uses for a successful XSS that can make you a lot of money! That’s why attackers will work to bypass a poorly configured CSP, and if it’s Trusted Types or a WAF, they will try every publicly known bypass from around the world. That’s how far an attacker will go.
Of course, there are cases where, as a result of increasing the difficulty, an XSS truly cannot be achieved. However, that is a matter of outcome. It’s better not to have the perception that you are safe just because you have multi-layered defenses. To close, let’s once again quote the words of OWASP31.
One final note: If deploying interceptors / filters as an XSS defense was a useful approach against XSS attacks, don’t you think that it would be incorporated into all commercial Web Application Firewalls (WAFs) and be an approach that OWASP recommends in this cheat sheet?
Recommended Countermeasures
Finally, let’s consider how we should approach XSS. To summarize everything we’ve discussed, the patterns of XSS that occur today are essentially as follows. Let’s list them again:
- A value that was thought to be safe was, in fact, not safe.
- A custom-built sanitizer was used but got bypassed, or an open-source sanitizer was used incorrectly.
- The defense mechanisms provided by a framework were not used correctly, or were simply not used at all.
- A lesser-known sink was embedded in a way that the framework does not protect against.
- A library was used without a proper understanding of its specifications.
Based on these patterns, the countermeasures we should take become clear. To avoid creating XSS vulnerabilities in this modern age, I believe the following points are crucial.
- Suspect all values. Programs are constantly changing and growing in complexity. It’s best to assume that accurately analyzing which values an attacker can control, and to what extent, is nearly impossible. A mindset of “no value is truly safe” is appropriate.
- When developing outside a framework, always use a widely-adopted open-source sanitizer to handle HTML. DOMPurify can be used on both the front-end and back-end and is recommended by OWASP. It’s a great choice. Also, whatever you use, do not modify the sanitized output in any way.
- When developing inside a framework, “correctly” understand and “always” use the provided defense mechanisms. First, you should properly understand the available security features by referring to the framework’s document. Then, you must use them wherever possible. If you can, it’s a good idea to introduce automated checks with linters in addition to code reviews.
- When handling URLs, check the scheme. Make sure that URLs with schemes like
javascript:are not allowed. - Do not dynamically generate scripts from input. JavaScript, in particular, has many complicated or unexpected grammars and behaviors, such as intervention in the prototype chain. A mechanism that generates and executes scripts based on user input is risky.
- Understand library behavior correctly. For any library generating HTML and JS, be sure to read its document thoroughly. In particular, information regarding security can often be found by searching for keywords like “warning,” “security,” “caution,” “deprecated,” and “preview”32. Please give it a try!
And after putting these methods into practice, here are the next steps you can take.
- Check for the presence of sinks with static analysis tools. While XSS sinks are diverse, they are also somewhat standardized, making inspection with static analysis tools like CodeQL or Semgrep effective. The ideal is to integrate this into your CI/CD pipeline and make it a condition for merging pull requests. If possible, running static analysis on bundled JavaScript can also help discover sinks hidden within libraries. Using a tool like Semgrep, which can scan only diff, can help keep execution times down. However, static analysis is not a silver bullet. Any rules may not be sufficient, so it is wise to avoid relying on it completely.
- Put risky modules in a sandboxed iframe. For example, it is effective to display the results of a WYSIWYG editor in an iframe and restrict what the iframe can do using
sandboxandallowattributes. - On top of that, utilize CSP and WAF. After implementing fundamental countermeasures, reducing risk with these additional layers is extremely effective.
In this post, we’ve taken a look at why XSS is still scary today. I hope this has helped you understand the background of how, no matter how much frameworks and sanitizers evolve, XSS can still arise from the smallest oversight.
Thank you for reading!👋
-
https://cwe.mitre.org/top25/archive/2020/2020_cwe_top25.html#cwe_top_25 ↩︎
-
https://cwe.mitre.org/top25/archive/2021/2021_cwe_top25.html#cwe_top_25 ↩︎
-
https://cwe.mitre.org/top25/archive/2022/2022_cwe_top25.html ↩︎
-
https://cwe.mitre.org/top25/archive/2023/2023_top25_list.html ↩︎
-
https://cwe.mitre.org/top25/archive/2024/2024_cwe_top25.html ↩︎
-
https://www.hackerone.com/resources/reporting/8th-hacker-powered-security-report ↩︎
-
https://blog.flatt.tech/entry/flatt_top10_2025#2025%E5%B9%B4%E7%89%88-Top-10 ↩︎
-
Interestingly, this paper introduced the idea that later became Trusted Types. The explainer of Trusted Types also mentions it. https://dl.acm.org/doi/pdf/10.1145/2643134 ↩︎
-
Google Vulnerability Reward Program. ↩︎
-
It says “It is noteworthy that the persistent storage contains both trustworthy and untrustworthy data in different entities of the same schema—no blanket assumptions can be made about the provenance of stored data.”. Also, “In reality, a large, nontrivial Web application will have hundreds if not thousands of branching and merging data flows into injection-prone sinks. Each such flow can potentially result in an XSS bug if a developer makes a mistake related to validation or escaping. Exploring all these data flows and asserting absence of XSS is a monumental task for a security reviewer, especially considering an ever-changing code base of a project under active development.” ↩︎
-
Let’s insert it to HTML on DevTools. Your browser will display a popup. ↩︎
-
https://web.dev/articles/howbrowserswork?hl=ja#browsers_error_tolerance ↩︎
-
Please refer to https://dl.acm.org/doi/pdf/10.1145/2643134 for the answer. ↩︎
-
https://cheatsheetseries.owasp.org/cheatsheets/Cross_Site_Scripting_Prevention_Cheat_Sheet.html#html-sanitization ↩︎
-
https://www.sonarsource.com/blog/pitfalls-of-desanitization-leaking-customer-data-from-osticket/ ↩︎
-
https://cheatsheetseries.owasp.org/cheatsheets/Cross_Site_Scripting_Prevention_Cheat_Sheet.html#html-sanitization ↩︎
-
https://www.sonarsource.com/blog/pitfalls-of-desanitization-leaking-customer-data-from-osticket/ ↩︎
-
It’s an example from CTF, but the first question of our “Flatt Security XSS Challenge” is about embedding a sanitized result to HTML, specifically, embedding the DOMPurify’s result to a textarea tag: https://challenge-xss.quiz.flatt.training/ ↩︎
-
https://cheatsheetseries.owasp.org/cheatsheets/Cross_Site_Scripting_Prevention_Cheat_Sheet.html ↩︎
-
https://github.com/illuminate/support/blob/19062b37bbdb1ef7a94f003adb2fd1cc775b47ae/Str.php#L565C1-L566C1 ↩︎
-
https://github.com/markedjs/marked?tab=readme-ov-file#warning--marked-does-not-sanitize-the-output-html-please-use-a-sanitize-library-like-dompurify-recommended-sanitize-html-or-insane-on-the-output-html- ↩︎
-
https://www.blackhat.com/docs/us-17/thursday/us-17-Lekies-Dont-Trust-The-DOM-Bypassing-XSS-Mitigations-Via-Script-Gadgets.pdf ↩︎
-
https://almanac.httparchive.org/en/2024/security#keywords-for-script-src ↩︎
-
https://cheatsheetseries.owasp.org/cheatsheets/Cross_Site_Scripting_Prevention_Cheat_Sheet.html ↩︎
-
https://cheatsheetseries.owasp.org/cheatsheets/Cross_Site_Scripting_Prevention_Cheat_Sheet.html ↩︎
-
https://speakerdeck.com/hamayanhamayan/ctfnowebniokeru-nan-yi-du-wen-ti-nituite?slide=26 ↩︎